
A numeric-based machine learning design for detecting organized retail fraud in digital marketplaces

In this section, we present the data and the methods used in our experiments. A brief description of the classifiers is given, as are the experimental settings.
Marketplace data
To detect the presence of ORC, we use historical data on activity and transactions from a popular worldwide online marketplace platform. We work with a sample of 3606 US-based sellers due to data labeling limits, and the primary data fields include product listing information and seller attributes. To ensure a consistent collection of listings and sellers, we restrict our research and modeling efforts to high-volume merchants (top sellers by listings within the last ninety days). The sample composition is summarized in Table 2.
The final data collection has a mixture of numeric, category, and text data types, with the text characteristics consisting primarily of the item’s title and description. In this paper, we rely more on the numeric and categorical features than the text features. From our data exploration, we do not find the text data to significantly improve the models’ performance. We summarize the final feature set in Table 3.
Data preprocessing and feature engineering
As illustrated in Fig. 3 above, we undertake a number of data preprocessing operations on the dataset. They entail resolving issues such as duplicate listings, missing data, and outliers. The duplicate removal step is critical because listings can be reposted on the Marketplace; therefore, we drop duplicate listings based on the seller ID, listing title, description, and price. Missing values are handled by deleting rows or columns. If the fraction of missing data in a column is less than 20%, the concerned rows are dropped; otherwise, the entire column is dropped. We have no reason to believe that this approach diminishes the dataset’s value. We discard values that are more than three standard deviations from the mean in columns such as “product price,” where the likelihood of outlier effects is significant.
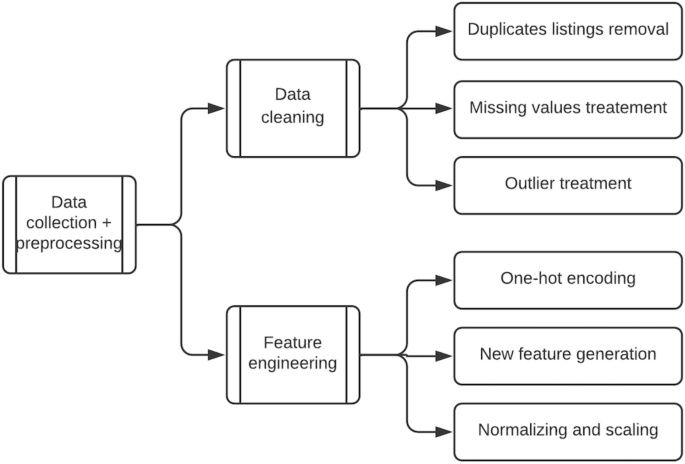
Data preprocessing steps.
Additionally, we use feature engineering to create new predictive features from existing ones.
Our feature engineering processes include one-hot encoding categorical variables, generating dummy columns for shipping type, and generating new features based on title and product description characteristics such as the number of words, the percentage of capitalized words, and the percentage of punctuation. The final data preprocessing step entails scaling the final feature set to ensure that all features are comparable in size. In this instance, we use standard scaling. Table 3 shows a list of these features and their descriptions.
The initial selection of these features is informed by discussions with ORC experts who have extensive experience identifying and mitigating organized retail fraud cases.
Classifiers
In the literature on fraud detection, classification techniques are frequently used to develop the detection model6. Classification is a supervised learning technique aimed at obtaining a discriminating function that categorizes samples45. Table 1 covers the most frequently used classifiers identified in the literature. We adapt these classifiers to our context as a first step in our search for the best-performing model. Additionally, we introduce new learners to improve on these baselines. We specifically add a balanced random forest classifier and a stacked ensemble of all the classifiers in our experiment. The balanced random forest classifier is designed to cope with the issue of imbalanced classes that exists in our data set. Below, we present brief descriptions of each classifier used:
Logistic regression
Logistic regression is similar to linear regression on classification tasks. It finds the values for coefficients \(\beta_1, \beta_2 , \ldots .,\beta_n\) that weigh each feature \(X_1 , X_2 , \ldots , X_n\) appropriately. It performs it predictions by transforming the output through a logistic function46. Thus, the probability of a listing being considered ORC fraud (class1) versus legitimate (class 0) can be given by:
$$P\left( class = 1 \right) = \frac11 + e^ – g\left( x \right) $$
where
$$g\left( x \right) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_n X_n$$
The weights are estimated from the input data using the maximum likelihood method. If \(P\left( class = 1 \right) > 0.5\), then the listing is fraudulent, and if \(P\left( class = 1 \right) < 0.5\), the listing is legitimate.
K-nearest neighbor
The k-nearest neighbor algorithm assumes that similar data points are close by in n-dimensional spaces. Similarity between the data points is often measured by the distance between the points (usually the Euclidean distance or the Mahalanobis distance)47. The class of a new data point is predicted by a validation of the local posterior probability of each class existing by the average class membership over its k-nearest neighbors. High cardinality data sets could pose challenges for this algorithm due to it being based on the distance between data points and its dimensions45.
Support vector machine
Support-vector machines (SVMs) are supervised learning models with algorithms that analyze data for classification or regression analysis48. The objective of the algorithm is to find a hyperplane in an n-dimensional space that distinctly classifies the data points. The choice is based on the hyperplane that has the most significant margin, which is the hyperplane that presents the maximum distance between data points in a binary class setup. The points closest to the hyperplane are termed “support vectors” because they influence the position and orientation of the hyperplane. The number of features also influences the dimension of the hyperplane46.
Naïve bayes
This classifier makes the naive assumption that all features in the input data are independent of each other while applying Bayes’ theorem, which describes the probability of an event, based on prior knowledge of conditions that might be related to the event. More specifically, it assumes all features independently contribute to the probability of the given class, which is often a strong assumption and unrealistic in practical settings. The algorithm assumes that the off-diagonal values of the covariance matrix are zero (independent). Then the joint distribution is the product of individual univariate densities (assuming that they are Gaussian in nature)49.
Decision tree
The decision tree algorithm is a supervised learning technique that can be used to solve both classification and regression problems. It uses tree representation to solve the problem, in which each leaf node corresponds to a class label and attributes are represented on the internal node of the tree. The branch or sub-tree represents a decision rule, and the topmost node is called a decision or a root node. CART is the most commonly used type of decision tree in which classification trees are applied to a target categorical variable and the tree is used to identify the class of the target variable. Regression trees, on the other hand, are applied to a continuous target variable, and the terminal nodes of the tree contain the predicted output variable values50.
Random forest
Random forest is one of the ensemble algorithms based on boot-strap aggregation (bagging technique). Ensemble is a machine learning technique that combines several base learning algorithms in order to produce a better predictive performance model, while bagging is a technique that uses the bootstrap algorithm to obtain a random sample from a given dataset with replacement and trains the base learners and aggregates their outputs to provide a lower variance model. It creates a set of decision trees on random samples of the training data and utilizes a voting mechanism based on the predictions of each individual tree to generate a final model. During training, it selects suboptimal splits for trees by randomness of the selected subset of the training set. As a result, different models are created, and their results are combined through the voting mechanism51
Gradient boosting
Gradient boosting52 builds an additive model in a forward stage-wise approach. A special algorithm, two-stage logistic likelihood, is used to solve a binary classification problem:
$$L\left( y,F \right) = \log \left( 1 + \texte^ – 2yF \right)$$
$$F\left( x \right) = \frac12log\left( \fracx)P(y = – 1 \right)$$
Gradient boosting of regression trees allows for the greedy optimization of arbitrary differential loss functions. At each fitting iteration, the solution (least square) tree is the one that minimizes the residuals, also known as the negative gradient of the binomial or multinomial deviance loss function. The gradient boosting method has two major parameters, the number of estimators and the learning rate. The former represents the number of boosting stages, where a large number often results in better performance, while the latter refers to a constant that controls the contribution of each tree to the model. There is often a trade-off between the learning rate and the number of estimators (n-estimators), making these two most important parameters for the algorithm.
Stacked generalization
Stacked generalization is an approach to minimizing the generalization error rate of one or more generalizers. With a given learning set, stacked generalization deduces the biases of the generalizers from the following steps: creating a partition of the learning set, training on one part of the partition, and then observing behavior on the other part. For a stacked model with multiple generalizers, it provides a more sophisticated strategy than the cross-validation winner-takes-all strategy for combining the individual generalizers53.
Data augmentation
Our data reveal an “unbalanced data problem”, which is a term that refers to an asymmetric distribution of data across classes38. The majority of machine learning algorithms do not perform well on unbalanced data, as the minority cases contribute less to the objective function minimization. To address the class imbalance issue, we adapt SMOTE37 and its variants to our environment. It is a technique for oversampling the minority class that involves manufacturing “synthetic” examples rather than oversampling with replacement. The synthetic examples are constructed using Euclidean distances between nearest neighbors, and the process involves: (1) calculating the distance between the feature vector and its nearest neighbors; (2) multiplying this difference by a random number between 0 and 1 and adding it to the feature vector. Mathematically:
$$x_gen = x + \alpha \left( x^\prime – x \right)$$
The data is then balanced by continuously inserting synthetic points between minority samples and neighboring data points. This strategy effectively causes the minority class’s choice region to become more general41. Because SMOTE in its original form is more appropriate for numeric data, we use its variation, SMOTENC, which can deal with categorical variables, in our data. The categories of newly generated examples are determined in this variation technique by selecting the most frequent category among the nearest neighbors present throughout the generation. A completely balanced dataset generated solely by SMOTENC may not be optimal, particularly for strongly skewed class distributions with extremely sparse minority class samples, which introduces a class mixture problem. Additionally, it is necessary to clean up the noisy instances generated by interpolating between marginal outliers and inliers. To address the aforementioned difficulties, we merged SMOTENC with two under-sampling techniques: Tomek’s links (TomekLinks) and edited nearest neighbors (ENN) to improve its effectiveness in dealing with class distributions that are out of balance. A more sophisticated strategy incorporates majority under-sampling into a classifier, resulting in an ensemble model. For example, random under-sampling was integrated with boosting and bagging and applied to both classes in a tree-based method called Balanced Random Forest54, which provides a balanced bootstrap sample to each tree of the forest.
The experimental setting
To conduct the fast-computing experiment, we randomly select 50 thousand rows by stratified sampling from the Marketplace listing data to ensure an unbiased representation of all subgroups. Since our experiments focus on building a fraud detection model constructed from numeric and categorical features, our first step involves developing a pipeline of these features from the listings data and matching them with marketplace account owners’ demographic, behavioral data, and transaction histories. For experiments 1 and 2, this step is followed by another pipeline that cleans the data by handling duplicates, missing values, and outliers, encodes categorical variables, and scales continuous features. In experiments 3 and 4 we add another pipeline that executes class asymmetry resolution by applying oversampling and/or undersampling techniques to create a balance between the ratios of the minority and majority classes. The final pipeline executes training, hyperparameter optimization, and evaluation of the classifiers. Tables 4 and 5 below show the hyperparameters used for tuning each classifier and the evaluation metrics applied to evaluate the performance of each classifier, respectively.
Hyperparameter tuning
Table 4 below shows the list of classifiers we use in our experiments and the respective hyperparameters we use to optimize their performance.
For each of the seven classifiers, the data are split into k-groups, (k = 5) in our case, where the choice of the value of k is informed by the literature review.
For each training iteration, k-1 groups of the data are used for training, while the remainder is used for validation. The groups are made, preserving the composition of the classes for our binary problem setting and each classifier is trained k times.
With k = 5, we have a fivefold cross-validation. The data are divided into 5 sets (see Fig. 4 below): set 1, set 2, set 3, set 4, and set 5. The algorithm is trained five times. In the first iteration, sets 1 through 4 are used as the training set, while set 5 is used as the validation set. In the second iteration, sets 1, 2, 3, and 5 are used as the training set and set 4 is used as the test set. This process is repeated until all the sets have been used for training and testing. The data are shuffled randomly before every split to minimize sample selection errors. The skill of each algorithm is summarized by a voting mechanism across all iterations as measured by their respective validation scores on the validation set.
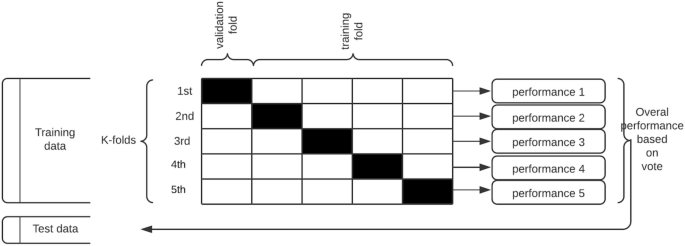
Repeated stratified k-fold cross validation procedure applied to each classification algorithm.
The holdout set is then used to test the performance of the trained classifier in a way that mimics the production environment, as illustrated in Fig. 4 below:
Finally, we use the evaluation metrics described in below to evaluate the performance across the classifiers.
Evaluation metrics
Literature in this area45 suggests the use of the evaluation metrics listed in Table 5 below, but we pay more attention to recall, which optimizes catching bad actors and minimizes false negatives (falsely predicting suspicious listings as not suspicious). The denotations tp, tn, fp, and fn used in the formulae column below carry their regular meaning in the classification context.
Additionally, we plot ROC-AUC curves as another measure of performance. This is important because some measures, such as accuracy, are unreliable in the case of imbalanced data sets.
Software implementation
We implement the experimental procedure based on the Python programming language using Scikit–Learn in combination with other common Python libraries such as NumPy, Pandas, Matplotlib, Seaborn and SciPy. For data acquisition and retrieval, we use structured query language (SQL) to query Hive tables where the data was initially stored.
link




